Schema Design
Summary
TLDRThis video discusses the importance of schema design, focusing on the snowflake and star schemas. The snowflake schema emphasizes normalized table structures with distinct data types for each table, ensuring no data repetition and allowing relationships through primary and foreign keys. In contrast, the star schema features a central fact table that supports denormalized data for faster reads, making it ideal for online analytical processing. Overall, the video highlights the differences between these schemas and their roles in online transaction processing and reporting.
Takeaways
- 📊 A schema is defined by the columns in a table, including their names and data types.
- ❄️ The snowflake schema supports normalized table structures, where data is not repeated across tables.
- 🏷️ In a snowflake schema, tables are related through primary and foreign keys, such as customer IDs and address IDs.
- 💻 The snowflake schema is designed for online transaction processing (OLTP), focusing on data integrity during writes.
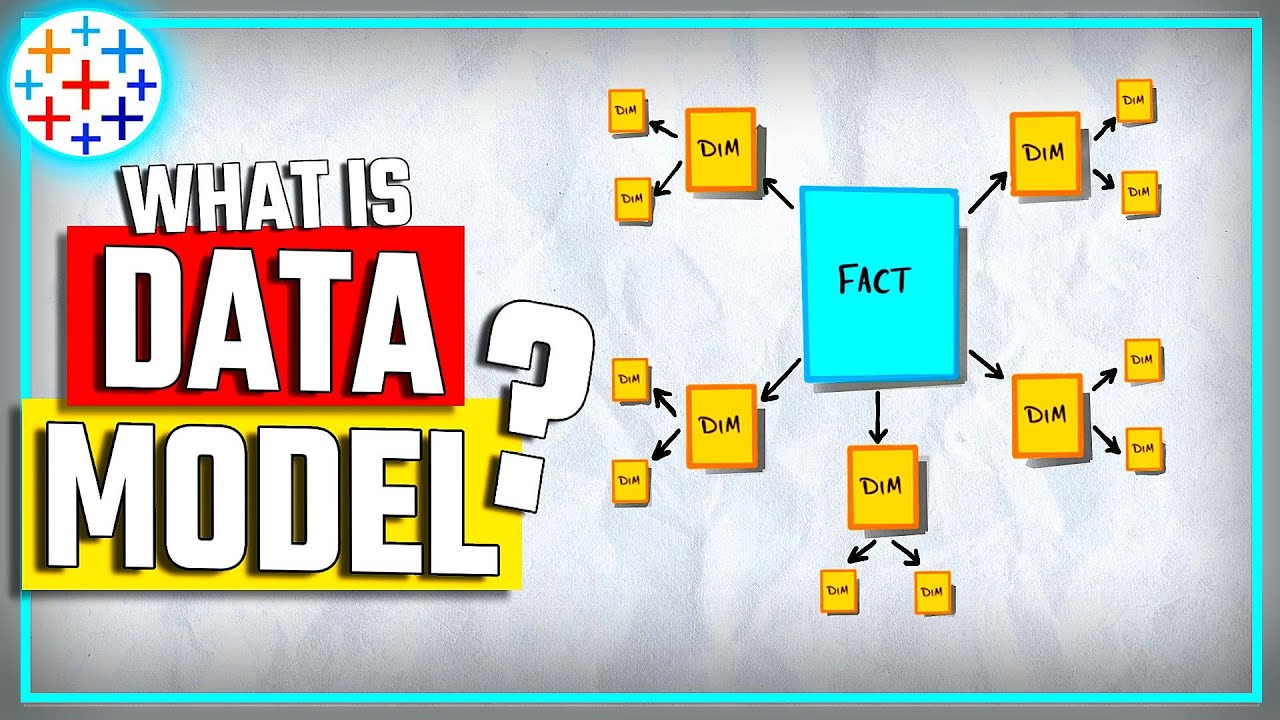
- ⭐ The star schema differs from the snowflake schema by supporting denormalized data, which means data may be repeated.
- 📈 The star schema is structured around a central fact table, which connects to dimension tables through foreign keys.
- 🚀 Star schemas are optimized for fast reads, making them suitable for online analytical processing (OLAP) and reporting.
- 🔗 Queries against a star schema allow for efficient one-hop access to related tables from the fact table.
- ⚙️ Both snowflake and star schemas are designed for specific types of data processing: OLTP and OLAP respectively.
- 📋 Understanding the differences between these schemas is essential for effective database design and data management.
Q & A
What is schema design in databases?
-Schema design refers to the organization of tables within a database, including the definition of columns and their data types.
What constitutes a snowflake schema?
-A snowflake schema is a normalized database structure where tables are linked through primary and foreign keys, allowing for efficient data organization and minimizing redundancy.
Can you provide an example of how a snowflake schema is structured?
-In a snowflake schema, a Customer table can be associated with an Addresses table, which is further linked to a Zip Codes table, while also connecting to Sales and Products tables.
How does a snowflake schema support data integrity?
-The snowflake schema ensures that data is organized into distinct tables that hold specific types of information, reducing redundancy and promoting consistency across related tables.
What is a star schema, and how does it differ from a snowflake schema?
-A star schema features a central fact table connected to several dimension tables, resulting in denormalized data that enables faster querying, in contrast to the more normalized structure of a snowflake schema.
Why is the star schema designed for fast reads?
-The star schema is designed for fast reads because it allows for quick access to related data through fewer joins, simplifying the retrieval process during analytical operations.
What types of processing are associated with the snowflake and star schemas?
-The snowflake schema is primarily used for Online Transaction Processing (OLTP), which focuses on writing data, while the star schema is designed for Online Analytical Processing (OLAP), which emphasizes reading data quickly for reporting.
How do primary and foreign keys function in a snowflake schema?
-In a snowflake schema, primary keys uniquely identify records in a table, while foreign keys establish relationships between tables, allowing for efficient data retrieval and integrity.
What are the advantages of using a snowflake schema?
-The advantages of using a snowflake schema include improved data integrity, reduced redundancy, and better organization of data across multiple related tables.
What are the key considerations when choosing between a snowflake and star schema?
-When choosing between a snowflake and star schema, consider factors like the need for data normalization versus denormalization, query performance requirements, and the type of processing (OLTP vs. OLAP) needed for your application.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тариф




5.0 / 5 (0 votes)
