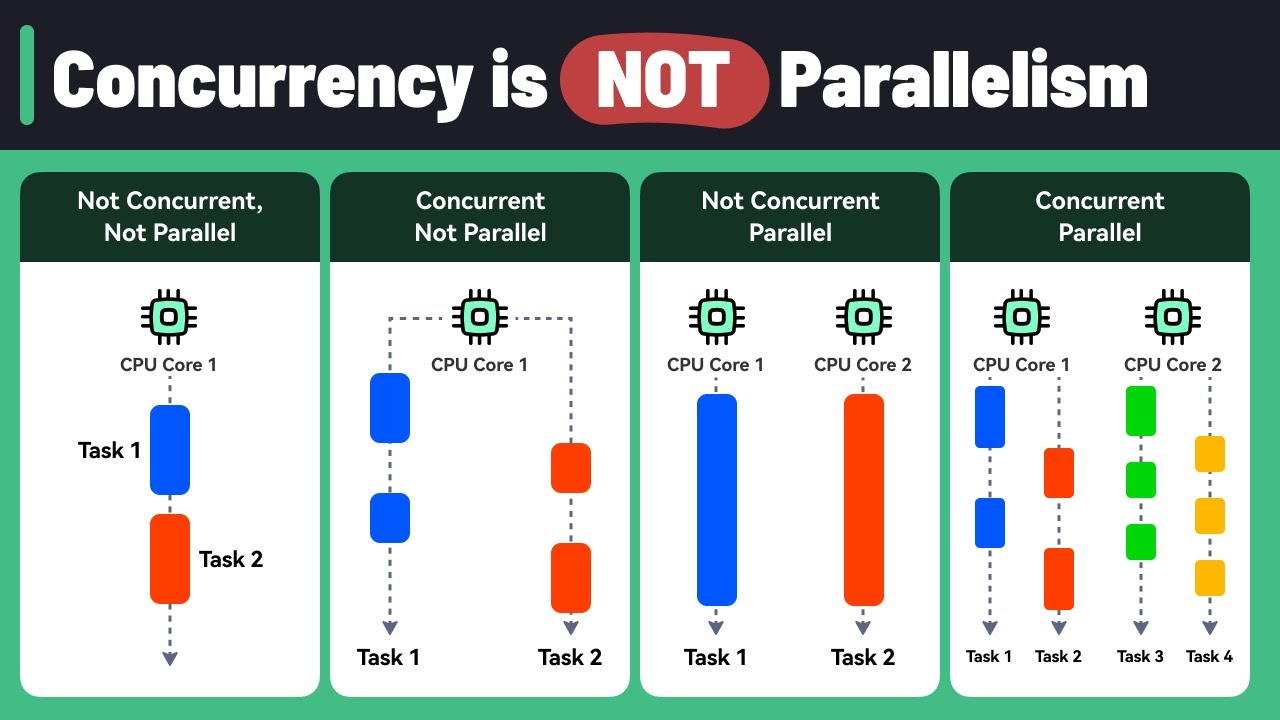
Data Parallelism Architecture
Summary
TLDRData parallelism is a parallelization technique that distributes data across multiple nodes, each processing its subset independently. It’s highly effective for large datasets and computationally intensive tasks, offering advantages like scalability, performance, and simplicity. However, it also has drawbacks, including communication overhead and limited use cases. Best suited for batch processing, machine learning, and stream processing, data parallelism excels when tasks can be independently executed on data partitions. Popular frameworks like Apache Spark and Apache Flink support this model, making it ideal for big data analytics, predictive analytics, and real-time data transformations.
Takeaways
- 😀 Data parallelism distributes data across multiple nodes, each applying the same operation on its allocated subset of data, enabling parallel computation.
- 😀 It is especially effective for large datasets, where tasks can be divided and executed simultaneously to reduce computational time.
- 😀 Data parallelism architecture splits the data into smaller partitions, each processed independently by separate tasks running the same operation.
- 😀 High parallel computation is enabled by distributing tasks across different cores or processors, allowing for efficient processing.
- 😀 Key advantages of data parallelism include scalability, performance improvements, and simplicity due to the uniform application of operations across data partitions.
- 😀 Scalability allows the addition of more nodes to handle growing data volumes while maintaining performance.
- 😀 Performance is improved through parallel computation, reducing computational time, particularly for large datasets and intensive operations.
- 😀 Simplicity in implementation comes from applying the same operation to each partition, making the model relatively easy to understand.
- 😀 Disadvantages include communication overhead, where nodes must synchronize and aggregate results, adding complexity for large node counts.
- 😀 Data parallelism is not suitable for tasks requiring complex interdependencies or shared state across tasks, limiting its use cases.
- 😀 Common use cases for data parallelism include batch processing, machine learning (especially in neural network training), and stream processing with large or partitioned data.
Q & A
What is data parallelism?
-Data parallelism is a form of parallel computation that distributes a large dataset across multiple nodes, where each node processes its allocated subset of data independently using the same operation.
How does data parallelism improve computational performance?
-Data parallelism improves performance by enabling simultaneous processing of different data partitions, significantly reducing computational time, especially for large datasets and computationally intensive tasks.
What are the key advantages of data parallelism?
-The main advantages of data parallelism are scalability (it can handle large data volumes by adding more nodes), performance (due to parallel computation), and simplicity (since the same operation is applied to each data partition).
What are the limitations or disadvantages of data parallelism?
-The primary disadvantages of data parallelism are communication overhead (nodes must synchronize and aggregate results, which can add time, especially with many nodes) and limited use cases (it works best when the same operation can be applied to all data partitions).
In which scenarios is data parallelism most effective?
-Data parallelism is most effective in batch processing, machine learning, stream processing, and when input/output data is partitioned evenly across nodes, making it ideal for large-scale data processing tasks like big data analytics and real-time data streams.
Why is data parallelism useful for machine learning algorithms?
-Data parallelism is useful in machine learning, particularly in neural network training, because it allows operations like weight updates across different layers to be performed in parallel, speeding up the training process.
How does data parallelism handle large datasets?
-Data parallelism handles large datasets by dividing them into smaller, manageable partitions that can be processed simultaneously across different nodes, enabling faster computations and reduced time to process the entire dataset.
What role do frameworks like Apache Spark play in data parallelism?
-Frameworks like Apache Spark facilitate data parallelism by providing tools to distribute tasks across nodes, process large datasets efficiently, and perform complex data transformations, such as ETL and predictive analytics, in parallel.
Can data parallelism be applied to real-time data processing?
-Yes, data parallelism is well-suited for stream processing, where real-time data can be processed by applying the same operation to incoming data streams concurrently.
What are the use cases of BitWorx in data parallelism?
-BitWorx is a framework designed for real-time stream processing, allowing the complex transformation of large, continuous streams of data using data parallelism to improve performance and reduce latency.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示




5.0 / 5 (0 votes)
