What is Azure Cosmos DB? | Azure Cosmos DB Essentials Season 1
Summary
TLDRWelcome to the Azure Cosmos DB essentials series with Mustafa, the technical product marketing manager. This series covers Cosmos DB concepts for developers of all levels. Season one explores the basics, starting with an introduction to Azure Cosmos DB, a NoSQL database designed for horizontal scaling and high availability. It discusses the importance of partitioning and replication for performance and fault tolerance. Cosmos DB's schema-less nature allows for flexible data models, supporting SQL API, graph data model via Gremlin API, and APIs for MongoDB and Cassandra. The series promises to showcase real-world use cases in upcoming episodes.
Takeaways
- 🌐 **Introduction to Azure Cosmos DB**: Mustafa introduces Azure Cosmos DB as a NoSQL database service.
- 📈 **Big Data Challenges**: Discusses the evolution from gigabytes to petabytes and the need for quick data access.
- 🔄 **Horizontal Scaling**: Explains how Cosmos DB scales horizontally to handle large data volumes and high throughput.
- 🔑 **Partitioning**: Highlights the importance of partitioning in improving database latency and throughput.
- 🌐 **Replication**: Describes how replication within and across regions enhances fault tolerance and availability.
- 📚 **Schema-less**: Emphasizes Cosmos DB's schema-less nature allowing for flexible data structures.
- 💾 **Data Models**: Cosmos DB supports multiple data models including document, key-value, graph, and wide-column store.
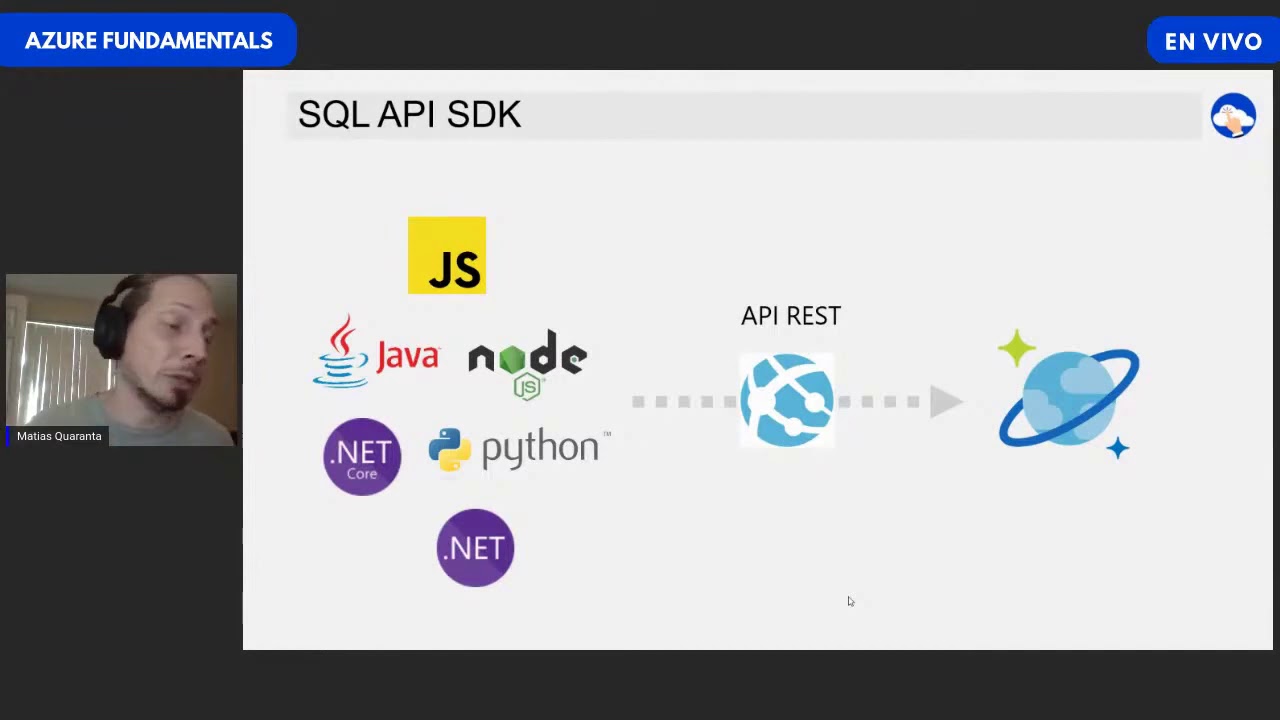
- 🔍 **SQL API**: Cosmos DB offers a SQL API for document and key-value data models.
- 🌐 **Global Distribution**: Cosmos DB can be geo-replicated across multiple Azure regions for higher availability.
- 🔄 **Consistency**: The series will cover the concept of consistency in a distributed database in later episodes.
Q & A
What is the main focus of the Azure Cosmos DB essentials series?
-The series focuses on discussing Cosmos DB concepts, tips, and tricks for both beginners and expert level Azure Cosmos DB developers.
Who is the presenter of the Azure Cosmos DB essentials series?
-Mustafa, the technical product marketing manager for Azure Cosmos DB.
What will be covered in season one of the series?
-Season one will cover the basics, starting with an introduction to Azure Cosmos DB, diving into use cases, discussing consistency in a distributed database, and ending with hybrid transactional and analytical processing and synapse link.
What is Azure Cosmos DB?
-Azure Cosmos DB is a NoSQL database service that offers horizontal scaling, replication, partitioning, and a flexible database schema.
How does Azure Cosmos DB handle the demands of big data?
-Azure Cosmos DB handles big data by scaling horizontally, which allows it to uncap the throughput and volume of data in the database, serving requests concurrently across multiple nodes.
What are the two kinds of partitions in Azure Cosmos DB?
-There are two kinds of partitions in Azure Cosmos DB: logical partitions, which are logical groups across items referenced through a partition key, and physical partitions, which are actual units of storage physically located in the Azure region.
Why is the partition key important in Azure Cosmos DB?
-The partition key is important because it tells the database engine where to look for data, which is a crucial part of optimizing the database for performance gains.
What are the two types of replication in Cosmos DB?
-There are two types of replication in Cosmos DB: replication within a region, which improves fault tolerance, and geo-replication outside of a region, which increases availability.
How does Cosmos DB's schema-less nature benefit developers?
-Cosmos DB's schema-less nature allows developers to work with structurally variable data without issues, making it easier to adapt and evolve applications as use cases change.
What data models does Cosmos DB support?
-Cosmos DB supports multiple data models including document, key-value, graph, and it provides APIs for SQL, MongoDB, and Cassandra to cater to different developer preferences and use cases.
How does the graph data model work in Cosmos DB?
-The graph data model in Cosmos DB uses the Gremlin API, which models complex systems with many-to-many relationships using edges and vertices, and traversal to navigate these relationships.
What are the benefits of using Cosmos DB for modern applications?
-Cosmos DB offers benefits such as high performance, availability, flexible schema, and support for multiple data models, making it suitable for modern applications that require high volumes of variable data without compromising on performance or availability.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示

Debugging and optimizing Azure Cosmos DB performance | Azure Friday

Azure Cosmos DB - Melhores Práticas | Big Data Masters

Azure Service Fabric - Tutorial 1 - Introduction
#AzureFundamentals 2020 | Fundamentos de Cosmos DB con Matías Quaranta

Simulasi Rapat Peluncuran Produk Baru

Key Parts of Project Initiation | Google Project Management Certificate
5.0 / 5 (0 votes)
