GCP - BigQuery
Summary
TLDRThis script offers an in-depth look at Google's BigQuery, a fully managed, serverless data warehouse solution designed for analytical use cases. It highlights BigQuery's ability to handle large-scale data analysis with its separation of storage and compute, allowing for scalability and cost-effectiveness. The script also covers various data ingestion methods, unique features like machine learning integration, and compares BigQuery with other cloud data warehouse solutions, emphasizing its serverless advantage and ease of use.
Takeaways
- 😀 Relational databases are characterized by ACID properties, supporting atomicity, consistency, isolation, and durability.
- 🔗 Cloud SQL is a managed SQL variant that offers vertical scaling, while Cloud Spanner provides horizontal scaling along with Cloud SQL's features.
- 📚 NoSQL databases offer flexible schemas and come in various types such as wide column, key-value pair, document, and case-based databases.
- 🌐 Bigtable is a wide column database with an HBase interface, making it suitable for big data projects.
- 📊 For analytical and business intelligence use cases, data warehouses like BigQuery are essential for ingesting and analyzing data from various sources.
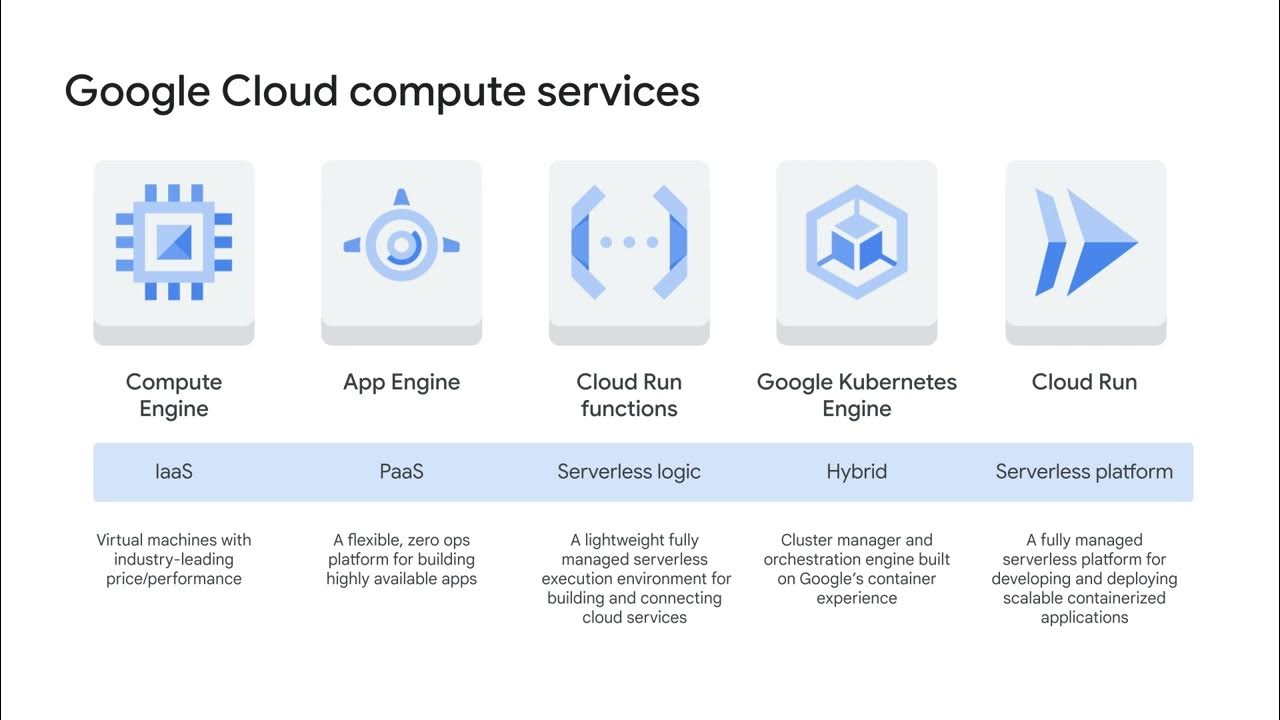
- 🛠️ BigQuery is Google Cloud's serverless, petabyte-scale, and cost-effective analytics data warehouse designed for OLAP use cases.
- 🌐 BigQuery's architecture decouples storage and compute, allowing independent scaling and providing flexibility and cost control.
- 💾 Storage in BigQuery is managed by Colossus, Google's global storage system optimized for reading large amounts of structured data.
- 🔍 BigQuery's compute is powered by Dremel, which executes SQL queries and manages the execution tree, mixers, and slots for processing power.
- 📈 BigQuery offers unique features like multi-cloud capabilities with BigQuery Omni, built-in machine learning with BigQuery ML, and integration with BI tools through BI Engine.
- 🌍 BigQuery provides public datasets, allowing users to query up to one terabyte of data per month at no cost from a repository of over 200 high-demand datasets.
Q & A
What are the key features of relational databases?
-Relational databases support ACID properties which include atomicity, consistency, isolation, and durability. They also support relational hierarchy.
What are the differences between Cloud SQL and Cloud Spanner in Google Cloud?
-Cloud SQL is a managed SQL variant that provides vertical scaling, while Cloud Spanner offers everything Cloud SQL provides plus horizontal scaling.
What types of NoSQL databases are mentioned in the script?
-The script mentions wide column, key-value pair, and document-based NoSQL databases.
Which Google Cloud services are used for NoSQL databases?
-Bigtable, which is a wide column database, and Memorystore, which is a managed in-memory data store, are mentioned as Google Cloud services for NoSQL databases.
What is the purpose of a data warehouse in the context of the script?
-A data warehouse is used for business intelligence use cases where all data is ingested at one place for reporting tools to provide actionable insights. It supports analysis on both batch and real-time data.
What is BigQuery and how does it differ from traditional data warehouses?
-BigQuery is Google Cloud's fully managed, serverless, and petabyte-scale analytics data warehouse designed for OLAP use cases. It differs from traditional data warehouses by decoupling storage and compute, allowing independent scaling and offering a serverless architecture.
How does BigQuery's architecture support its serverless nature?
-BigQuery's architecture decouples storage and compute, connected via a petabit network, allowing it to scale independently on demand without the need for managing any infrastructure.
What are the components of BigQuery's architecture?
-BigQuery's architecture includes Dremel for compute, Colossus for storage, Jupiter for the petabit network, and Borg for orchestration.
How does BigQuery handle data ingestion?
-BigQuery allows data ingestion through streaming, batch loading, or bulk data uploads. Data can be accessed via SQL compliant clients, REST API, web UI, CLI, and client libraries in multiple languages.
What are some unique features of BigQuery?
-BigQuery offers multi-cloud capabilities with BigQuery Omni, built-in machine learning with BigQuery ML, integration with Vertex AI, BI Engine for accelerating BI workloads, connected sheets for analyzing data in Google Sheets, geospatial data types, federation to process external data sources, and access to public datasets.
How does BigQuery compare to other cloud data warehouse solutions like AWS Redshift and Snowflake?
-BigQuery is a true serverless solution with no need to manage nodes or infrastructure, offering on-demand or flat-rate pricing based on slots, and native AI/ML support with Google Cloud services.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード



5.0 / 5 (0 votes)
