Deep Learning(CS7015): Lec 9.3 Better activation functions
Summary
Please replace the link and try again.
Takeaways
- 😀 ReLU ist die Standardaktivierungsfunktion in tiefen Faltungsnetzwerken, weil sie einfach und effektiv ist.
- 😀 Ein Problem von ReLU ist, dass Neuronen „sterben“ können, wenn ihre Eingabe negativ ist, da sie dann null ausgibt.
- 😀 Leaky ReLU wurde eingeführt, um das Problem der toten Neuronen zu lösen, indem es für negative Eingaben eine kleine, nicht null Antwort liefert.
- 😀 Parametric ReLU (PReLU) erweitert leaky ReLU, indem der negative Slope als trainierbarer Parameter eingeführt wird.
- 😀 Exponential ReLU ist eine teurere Variante von ReLU, die jedoch ähnliche Vorteile bietet, aber mit höherem Rechenaufwand.
- 😀 Sigmoid- und Tanh-Funktionen sind in der Praxis oft problematisch, besonders bei tiefen Netzwerken, da sie zu einer Sättigung der Gradienten führen können.
- 😀 Maxout Neuronen sind eine Generalisierung von ReLU und leaky ReLU, da sie den maximalen Wert aus mehreren linearen Funktionen auswählen.
- 😀 Die Wahl des Aktivierungsfunktion hängt von den spezifischen Anforderungen des Modells ab; ReLU funktioniert in den meisten Fällen gut, aber leaky ReLU und Maxout bieten nützliche Alternativen.
- 😀 Sigmoid- und Tanh-Funktionen werden immer noch in RNNs und LSTMs verwendet, wo ihre spezifischen Eigenschaften vorteilhaft sind.
- 😀 Der Übergang von Sigmoid/Tanh zu ReLU und seinen Varianten ist Teil einer größeren Entwicklung im Training tiefer neuronaler Netzwerke, die auf bessere Optimierungsmethoden abzielt.
Q & A
Was ist das Hauptproblem von ReLU, das während des Trainings auftreten kann?
-Das Hauptproblem von ReLU ist das sogenannte 'Dead Neuron Problem', bei dem Neuronen dauerhaft Null ausgeben und somit nicht mehr an der Anpassung des Modells beteiligt sind. Dies passiert, wenn der Eingang der ReLU-Funktion negativ ist und die Funktion auf Null abfällt.
Was ist eine Lösung für das Dead Neuron Problem bei ReLU?
-Eine Lösung für das Dead Neuron Problem ist die Verwendung von Leaky ReLU, bei dem anstelle einer Null eine sehr kleine Zahl für negative Eingabewerte ausgegeben wird. Dies ermöglicht es, dass auch bei negativen Eingaben ein Gradientenfluss durch das Netzwerk erfolgt.
Wie unterscheidet sich Leaky ReLU von der klassischen ReLU?
-Leaky ReLU unterscheidet sich von ReLU darin, dass es für negative Eingabewerte eine kleine, konstante Zahl (z. B. 0,01) zurückgibt, anstatt Null. Dies sorgt dafür, dass ein kleiner Gradientenfluss auch für negative Eingaben möglich bleibt und das Dead Neuron Problem vermieden wird.
Was ist Parametric ReLU (PReLU) und wie unterscheidet es sich von Leaky ReLU?
-Parametric ReLU (PReLU) ist eine erweiterte Version von Leaky ReLU, bei der der Slope (die Steigung) für negative Eingaben als trainierbarer Parameter festgelegt wird. Dies bedeutet, dass der Wert des Gradientenflusses für negative Eingaben während des Trainings angepasst wird, anstatt konstant zu sein.
Warum wird Leaky ReLU als effizient angesehen?
-Leaky ReLU wird als effizient angesehen, weil es keine komplexen Berechnungen wie Exponentialfunktionen oder Quadrate erfordert. Es ist daher schneller und ressourcenschonender als viele andere Aktivierungsfunktionen, während es gleichzeitig verhindert, dass Neuronen während des Trainings 'sterben'.
Was sind die Vor- und Nachteile von Exponential ReLU?
-Exponential ReLU hat den Vorteil, dass es ein sanfteres und flexibleres Aktivierungsschema bietet, das ähnliche Vorteile wie ReLU bietet, aber auch bei negativen Eingabewerten eine kleine Aktivierung ermöglicht. Der Nachteil ist jedoch, dass es rechenintensiver ist, da es eine Exponentialfunktion beinhaltet.
Was ist der Hauptnachteil der Maxout-Neuronen?
-Der Hauptnachteil von Maxout-Neuronen besteht darin, dass sie die Anzahl der zu lernenden Parameter verdoppeln. Da Maxout mehrere lineare Funktionen kombiniert, erfordert es zusätzliche Parameter, was die Komplexität und den Trainingsaufwand des Modells erhöht.
Warum werden Sigmoid und Tanh in Convolutional Neural Networks (CNNs) nicht verwendet?
-Sigmoid und Tanh werden in CNNs nicht verwendet, weil sie zu Problemen wie dem Sättigungsproblem führen, bei dem die Gradienten während des Trainings verschwinden. Dies erschwert das Optimieren des Modells, besonders bei tiefen Netzwerken. ReLU und seine Varianten sind in dieser Hinsicht besser geeignet.
Welche Aktivierungsfunktion ist in der Praxis die Standardwahl für CNNs?
-In der Praxis ist ReLU die Standardaktivierungsfunktion für Convolutional Neural Networks (CNNs). Sie wird aufgrund ihrer Einfachheit und Effizienz bevorzugt, auch wenn sie gewisse Probleme wie das Dead Neuron Problem aufweisen kann.
Wie werden Sigmoid und Tanh weiterhin verwendet, trotz ihrer Nachteile in CNNs?
-Sigmoid und Tanh werden weiterhin in speziellen Architekturen wie Long Short-Term Memory (LSTM) Netzwerken und Recurrent Neural Networks (RNNs) verwendet, da diese Netzwerke besser mit sequenziellen Daten umgehen können und diese Aktivierungsfunktionen dort besser funktionieren.
Outlines

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenMindmap

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenKeywords

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenHighlights

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenTranscripts

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenWeitere ähnliche Videos ansehen
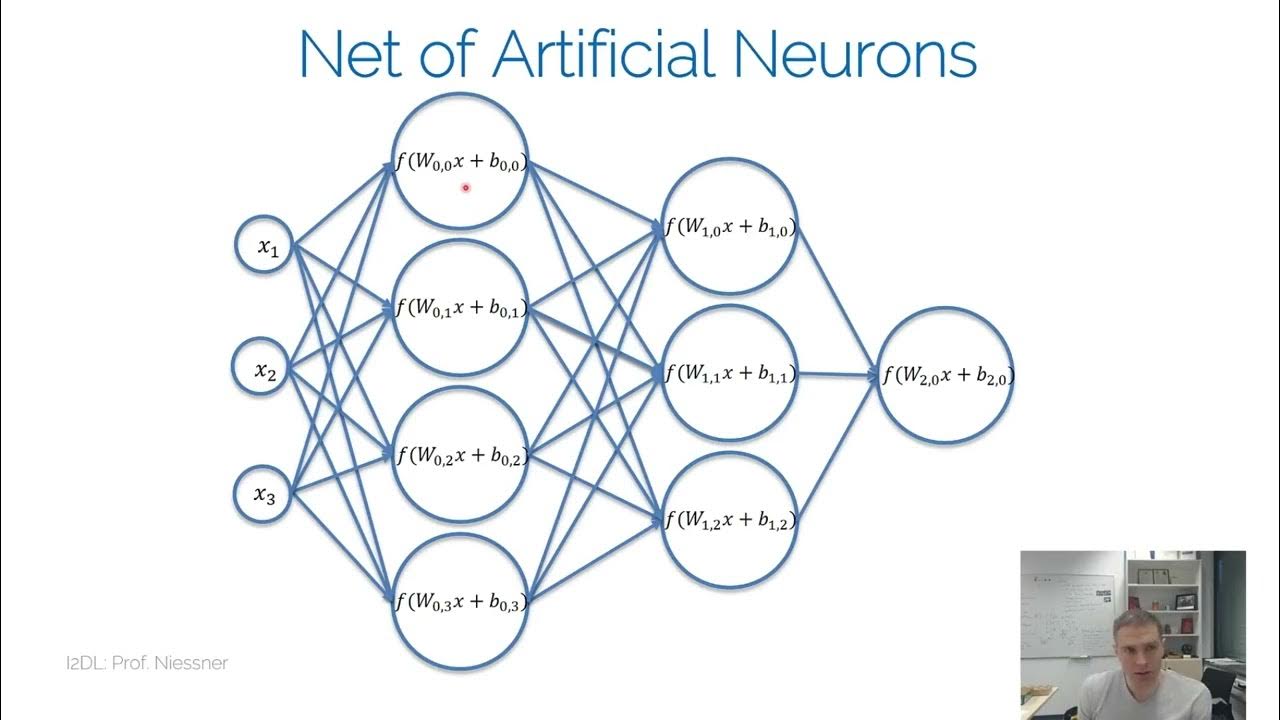
I2DL NN

PyTorch Tutorial 12 - Activation Functions

Activation Functions In Neural Networks Explained | Deep Learning Tutorial

Deep Learning: In a Nutshell

CNN Architecture | LeNet -5 Architecture

EfficientML.ai Lecture 2 - Basics of Neural Networks (MIT 6.5940, Fall 2024)

Complete Road Map To Prepare For Deep Learning🔥🔥🔥🔥
5.0 / 5 (0 votes)