Supervised vs. Unsupervised Learning
Summary
TLDRThis video script delves into the distinctions between supervised and unsupervised learning in machine learning. Supervised learning uses labeled data to train algorithms, focusing on classification and regression tasks, while unsupervised learning uncovers patterns in unlabeled data through clustering, association, and dimensionality reduction. The script also introduces semi-supervised learning as a middle ground, combining labeled and unlabeled data, which is particularly beneficial for large datasets with limited labeling. The choice between these methods depends on the nature of the data and the objectives of the analysis.
Takeaways
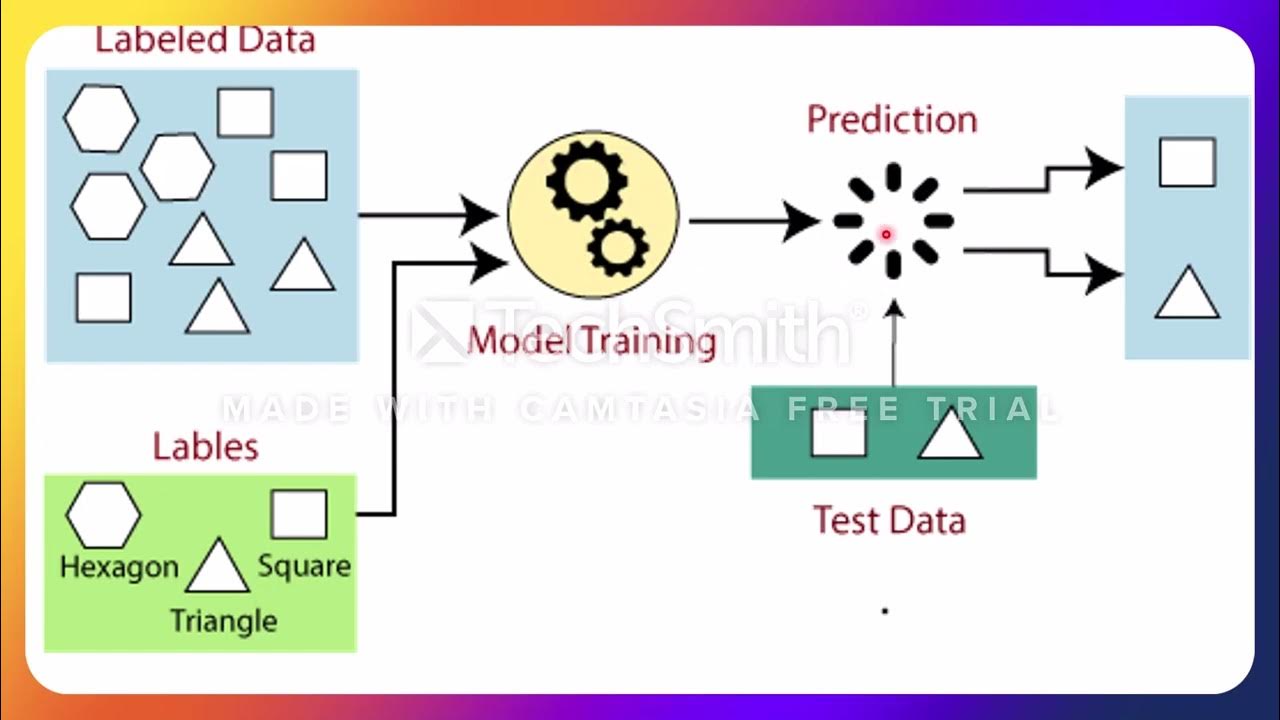
- 📚 Supervised learning uses labeled input and output data, while unsupervised learning operates without labels.
- 🔍 In supervised learning, algorithms are trained on datasets where the correct outputs are known, allowing them to learn and generalize to new data.
- 📊 Supervised learning includes classification (discrete outputs like 'spam' or 'not spam') and regression (continuous outputs like price or probability).
- 🤖 Unsupervised learning algorithms discover patterns in data without human guidance, focusing on tasks like clustering, association, and dimensionality reduction.
- 👥 Clustering in unsupervised learning groups similar data points together, useful for customer segmentation in business.
- 🔗 Association in unsupervised learning identifies relationships between variables, often used in market basket analysis to find commonly purchased items together.
- 🔎 Dimensionality reduction in unsupervised learning minimizes data variables while retaining information, useful for pre-processing data like image noise reduction.
- 💡 Supervised learning models are generally more accurate due to the guidance of labeled data but require more human effort for data labeling.
- 🌐 Unsupervised learning models can handle large, unlabeled datasets and discover hidden patterns that might be missed by supervised approaches.
- 🎯 Semi-supervised learning offers a middle ground, using both labeled and unlabeled data, which is beneficial when labeled data is scarce or expensive to obtain.
Q & A
What is the fundamental difference between supervised and unsupervised learning?
-Supervised learning uses labeled input and output data, while unsupervised learning does not use labels and instead discovers patterns in the data.
How does a supervised learning algorithm improve its performance?
-A supervised learning algorithm improves by iteratively making predictions on training data, adjusting its parameters based on the correct answers, and measuring its accuracy.
What are the two main subcategories of supervised learning mentioned in the script?
-The two main subcategories of supervised learning are classification and regression.
Can you provide examples of classification algorithms mentioned in the script?
-Examples of classification algorithms mentioned are linear classifiers, support vector machines (SVMs), decision trees, and random forests.
What does regression in supervised learning predict and give examples of algorithms used?
-Regression in supervised learning predicts a continuous value, such as price or probability. Examples of regression algorithms are linear regression and logistic regression.
What are the three main tasks that unsupervised learning models are used for?
-The three main tasks for unsupervised learning models are clustering, association, and dimensionality reduction.
How does clustering in unsupervised learning work and what is an example of its application?
-Clustering groups similar data points together. An example application is customer segmentation, where customers are grouped based on similarities like age, location, or spending habits.
What is association in unsupervised learning and how is it used in market basket analysis?
-Association in unsupervised learning looks for relationships between variables in the data. It's used in market basket analysis to determine which items are often bought together.
What is dimensionality reduction and how does it benefit data preprocessing?
-Dimensionality reduction is a technique that reduces the number of variables in data while preserving as much information as possible. It's often used in data preprocessing to remove noise from data, such as visual images.
Why might supervised learning be more accurate than unsupervised learning?
-Supervised learning might be more accurate because it uses labeled data to train the model, allowing it to learn from the correct outputs and adjust its predictions accordingly.
What are the advantages of unsupervised learning over supervised learning?
-Unsupervised learning can handle data that is not labeled and can discover hidden patterns that supervised learning might miss. It can also process large volumes of data in real time without the need for human intervention.
What is semi-supervised learning and when is it particularly useful?
-Semi-supervised learning is a middle ground where both labeled and unlabeled data are used for training. It's particularly useful when it's difficult to label a large volume of data, such as in medical imaging.
How can semi-supervised learning improve medical image analysis?
-Semi-supervised learning can improve medical image analysis by using a small amount of labeled data to train the model, which can then more accurately predict outcomes for unlabeled data, such as identifying potential tumors or diseases.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

Classification & Regression.

#6 Machine Learning Specialization [Course 1, Week 1, Lesson 2]
L8 Part 02 Jenis Jenis Learning

Aprendizado de Máquina: Supervisionado e Não Supervisionado

TYPES OF MACHINE LEARNING-Machine Learning-20A05602T-UNIT I – Introduction to Machine Learning

DIFERENCIA ENTRE APRENDIZAJE SUPERVISADO Y NO SUPERVISADO
5.0 / 5 (0 votes)
