Google SWE teaches systems design | EP22: HBase/BigTable Deep Dive
Summary
TLDRIn this video, the host celebrates the one-month anniversary of their channel and dives into a detailed exploration of HBase, a NoSQL database modeled after Google's Bigtable. They discuss HBase's architecture, including its master and region servers, and how it uses LSM trees and SS tables for efficient random read and write performance. The video compares HBase with Cassandra, highlighting differences in their use cases, and touches on HBase's strong consistency and integration with big data processing frameworks like MapReduce and Spark. The host concludes by differentiating HBase's suitability for data lakes and analytics from traditional data warehouses.
Takeaways
- 🎉 The speaker celebrated the one-month anniversary of their channel with 260 subscribers.
- 📚 The video discusses HBase, a NoSQL database modeled after Google's Bigtable.
- 🔍 The speaker had to research HBase deeply due to the lack of quality information online, with many blog posts plagiarizing each other.
- 🌐 HBase uses LSM trees and SS tables to achieve better random read and write performance with lower latency compared to HDFS.
- 📈 HBase is a wide column store NoSQL database, similar to Cassandra but with significant differences.
- 🔑 HBase organizes data with a single row key and column families, where the row key can be composed of multiple parts.
- 💾 The architecture of HBase includes a master server for metadata and operations, region servers for handling data, and uses ZooKeeper for coordination.
- 🚀 HBase is not ideal for time series data due to potential hotspots caused by sequential writes to a single partition.
- ♻️ Writes in HBase first go to an in-memory LSM tree and then are flushed to SS tables, which are stored in a column-oriented format on HDFS.
- 🔒 HBase provides strong consistency for data replication, ensuring all writes are successful before being considered complete.
- 📊 HBase integrates well with analytics engines like MapReduce, Spark, and Tez due to its column-oriented storage on HDFS.
- 🚀 HBase is suitable for use cases involving large-scale batch jobs and stream processing, especially in a data lake scenario.
Q & A
What is the significance of the one-month anniversary mentioned in the script?
-The one-month anniversary mentioned in the script signifies that the speaker's channel has reached a milestone of one month, and they are excited to have 260 subscribers, indicating growth and engagement with the audience.
What is HBase and why is it discussed in the script?
-HBase is a wide column NoSQL storage database that is discussed in the script due to its relevance to the topic of NoSQL databases and its use of LSM trees and SS tables for better performance compared to HDFS.
What are the key differences between HBase and Cassandra mentioned in the script?
-The script mentions that while both HBase and Cassandra are wide column NoSQL databases, they differ significantly in terms of their architecture, replication strategy, and suitability for different use cases such as real-time transactions and analytics processing.
How does HBase achieve better random read and write performance compared to HDFS?
-HBase uses LSM trees and SS tables to achieve better random read and write performance. This allows for lower latency reads and writes, as opposed to the high latency and sequential appends/truncates of HDFS.
What is the role of the master server in HBase?
-The master server in HBase is responsible for storing file metadata, handling operations on the metadata, and managing the location of files. It also performs range-based partitioning based on the row key and can split partitions if they become too large or have too much load.
What is the purpose of the region server in HBase?
-The region server in HBase handles the actual storage and retrieval of data. It runs on HDFS data node servers and maintains an in-memory LSM tree data structure for efficient writes. It also communicates with HDFS for data replication and storage of SS tables.
How does HBase integrate with HDFS for data replication?
-HBase integrates with HDFS by using the HDFS data node as the region server and leveraging the replication pipeline of HDFS to maintain the required replication factor for SS tables, ensuring data redundancy and fault tolerance.
What is the significance of column-oriented storage in HBase?
-Column-oriented storage in HBase allows for high read throughput when reading values over a column or partition, which is beneficial for analytics processing and batch jobs that require scanning large amounts of data.
How does HBase differ from a traditional SQL database in terms of data handling?
-HBase, being a NoSQL database, does not have structured data and does not support native joins like a SQL database. Instead, it requires batch processes or other methods to perform data associations and joins.
What is the advantage of using HBase for a data lake scenario?
-Using HBase for a data lake scenario allows for the dumping of unstructured data into a format that can later be used for analytics. HBase provides the advantage of good read and write performance for random access, which is useful for transaction processing in addition to analytics.
What are the limitations of HBase when it comes to real-time transaction processing?
-While HBase uses LSM trees for efficient writes, it may not handle writes as fast as Cassandra, which is designed for real-time transaction processing. HBase is more suited for scenarios where high read throughput for analytics is required.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade Now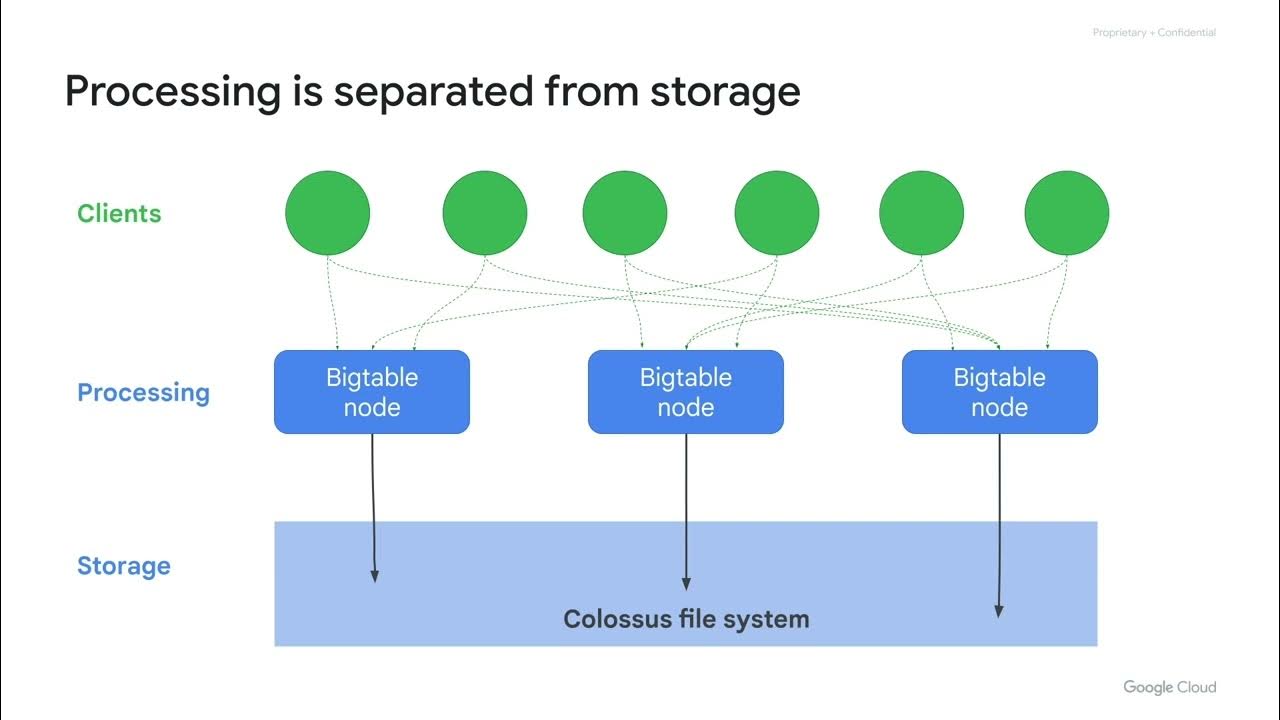




5.0 / 5 (0 votes)