Fine Tuning, RAG e Prompt Engineering: Qual é melhor? e Quando Usar?
Summary
TLDRThis video script explores the differences between fine-tuning, prompt engineering, and retrieval-augmented generation (RAG) in the context of large language models (LLMs). The speaker addresses common questions on when to use each technique and highlights the importance of understanding these tools as AI advances. The script explains that LLMs are statistical models predicting the next word based on context, not storing knowledge. It delves into prompt engineering as crafting prompts for desired responses, RAG as generating information based on accessible content, and fine-tuning as adjusting the model's behavior for specific tasks. The speaker dispels myths about fine-tuning, emphasizing its practicality and potential in enhancing AI applications.
Takeaways
- 😀 Large Language Models (LLMs) are statistical models that predict the next word based on the context of previous words, rather than having a knowledge library.
- 🧐 Prompt Engineering involves crafting prompts to guide the AI to provide a desired response, including setting context, style, tone, rules, dynamic context, and format.
- 🔍 Retrieval-Augmented Generation (RAG) is a technique that uses external content to enhance the AI's responses, involving data preparation, embedding generation, and data retrieval based on similarity.
- 🛠 Fine-tuning adjusts a model's behavior and style to better suit specific tasks or applications, without necessarily requiring a vast amount of data or being extremely costly.
- 🔗 Combining Fine-tuning, Prompt Engineering, and RAG can lead to more effective AI applications by leveraging the strengths of each technique.
- 📚 The script emphasizes the importance of understanding these AI tools to choose the right one for different scenarios and to enhance the model's performance.
- 💬 The speaker invites feedback on the content to adjust future videos, indicating an interest in covering both technical and conceptual aspects of AI.
- 📉 LLMs can sometimes generate responses that are statistically likely but not based on factual reality, which is why they should not be seen as infallible knowledge sources.
- 📝 The process of RAG involves segmenting data, creating embeddings for vector representation, storing these vectors, and then using them to retrieve relevant information.
- 🎯 Fine-tuning is not about teaching the model new content but adjusting its parameters to align with specific goals or styles of response.
- 🔑 The video script is an educational resource aiming to clarify the concepts of fine-tuning, RAG, and Prompt Engineering for better application in AI models.
Q & A
What are the main differences between fine-tuning, Tunning Rag, and Prompt Engineering in the context of large language models?
-Fine-tuning adjusts the behavior and style of a language model to suit specific needs. Tunning Rag, or Retrieval-Augmented Generation, uses external content to inform the model's responses. Prompt Engineering involves crafting the input to the model to elicit a desired response.
Why is understanding the context important when working with large language models?
-Understanding context is crucial because large language models predict the next word based on the context of previous words. Without proper context, the model may generate responses that are statistically likely but not necessarily accurate or relevant.
What is the role of Prompt Engineering in eliciting a response from a language model?
-Prompt Engineering is about constructing the input or 'prompt' to the model in such a way that it brings an appropriate response. It involves setting the context, style, tone, and rules that the model should follow in its response.
Can you explain the process of Retrieval-Augmented Generation (RAG) in the context of language models?
-RAG involves retrieving and using external content to inform the model's responses. It includes preparing data, segmenting it, generating embeddings for the data, storing it, and then using the embeddings to search for relevant information in the database to complement the model's output.
What are some common misconceptions about fine-tuning large language models?
-Some misconceptions include the belief that fine-tuning is very expensive, requires millions of examples, teaches the model new content, and is a substitute for RAG. In reality, fine-tuning can be affordable, needs fewer examples than thought, adjusts parameters without adding content, and complements rather than replaces RAG.
How does fine-tuning help in adjusting the style and behavior of a language model?
-Fine-tuning adjusts the model's parameters to change its behavior and style. This can make the model respond in a specific way that is tailored to particular tasks or applications, such as generating responses in a certain tone or format.
What is the advantage of using a combination of fine-tuning, RAG, and Prompt Engineering?
-Combining these techniques leverages the strengths of each. Fine-tuning adjusts the model's behavior, RAG provides up-to-date and specialized content, and Prompt Engineering ensures the model's responses are directed towards the desired outcome, leading to more effective and tailored applications.
How does the concept of embeddings play a role in RAG?
-Embeddings are the vector representations of the text segments. They allow the model to search for similar contexts or information in the database, which can then be used to inform the model's responses, enhancing accuracy and relevance.
What are some practical applications of fine-tuning, RAG, and Prompt Engineering in developing AI solutions?
-These techniques can be used to develop AI solutions for customer service chatbots, content creation, specialized knowledge bases, and any application where the AI needs to generate contextually appropriate and accurate responses.
How can fine-tuning make smaller models perform specialized tasks more effectively?
-Fine-tuning can adjust smaller models to perform specialized tasks by aligning their behavior and responses with specific objectives. This can make them faster and more cost-effective for certain applications compared to larger models.
What is the significance of segmenting data in the RAG process?
-Segmenting data is important because it breaks down large amounts of content into manageable pieces. Proper segmentation ensures that related information is kept together, which is crucial for the model to generate coherent and contextually accurate responses.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示
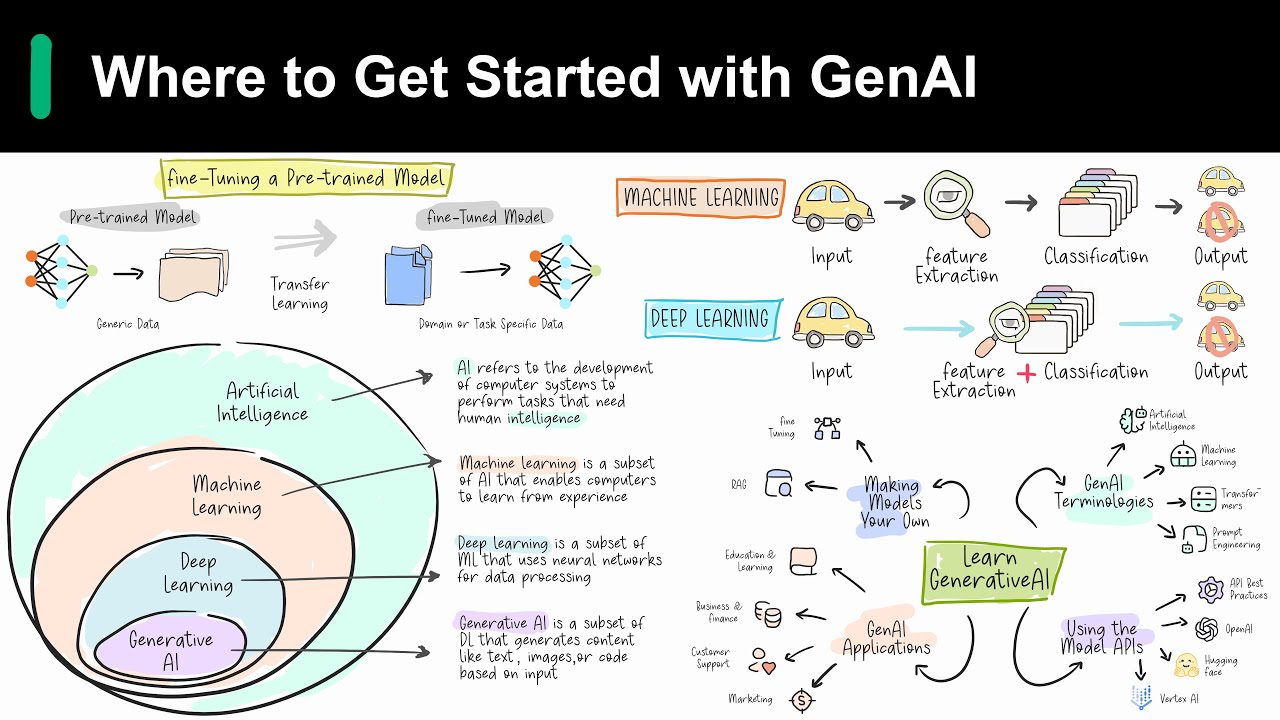
Introduction to Generative AI

RAG vs Fine-Tuning vs Prompt Engineering: Optimizing AI Models

The Vertical AI Showdown: Prompt engineering vs Rag vs Fine-tuning
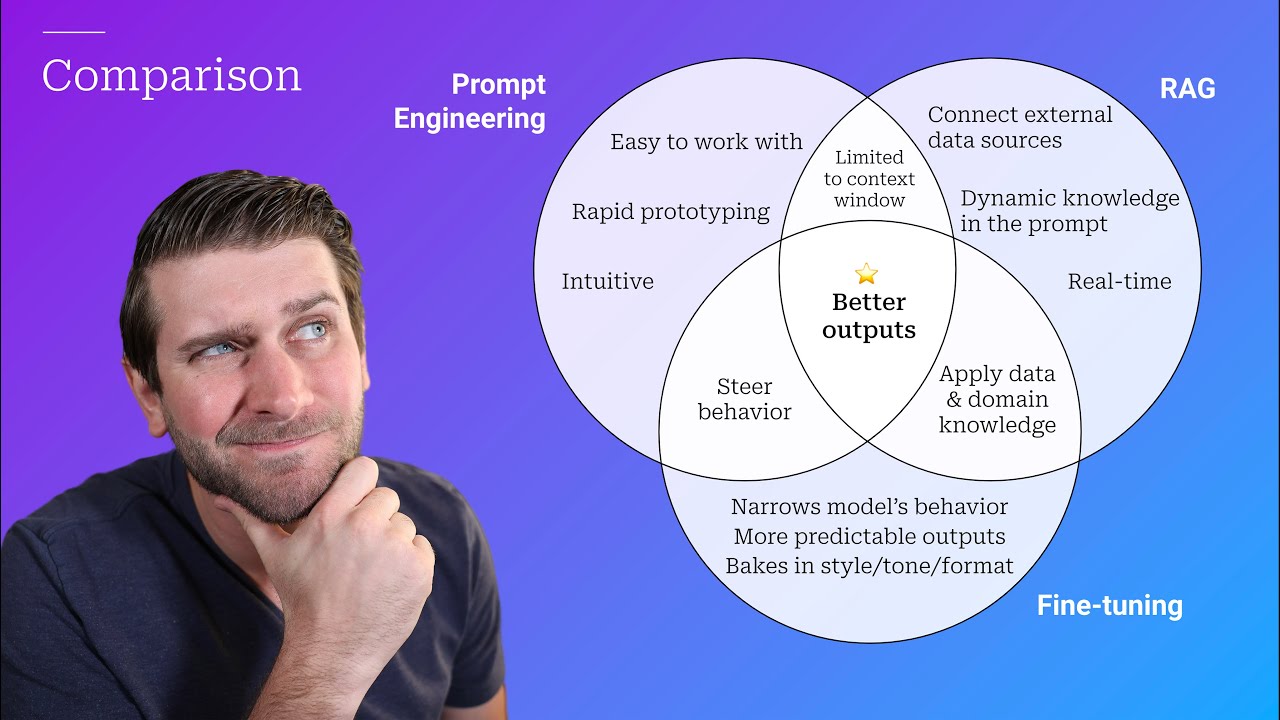
Prompt Engineering, RAG, and Fine-tuning: Benefits and When to Use

A basic introduction to LLM | Ideas behind ChatGPT

Retrieval Augmented Generation - Neural NebulAI Episode 9
5.0 / 5 (0 votes)
