3 - Mesures de position, mesures de dispersion: les principes
Summary
TLDRCe chapitre explore les mesures de position et de dispersion pour synthétiser les données quantitatives et qualitatives. Il explique la moyenne et la médiane, leurs avantages et limites, notamment en fonction de la symétrie des distributions et de la robustesse face aux valeurs extrêmes. Les mesures de dispersion, telles que les quartiles et l'écart-type, sont détaillées, avec leurs interprétations, usages et propriétés mathématiques. L'accent est mis sur l'intérêt pratique et historique de l'écart-type, notamment pour de grands échantillons, tout en soulignant l'importance de choisir la mesure adaptée selon le contexte et les objectifs de l'analyse.
Takeaways
- 😀 Un fichier de données peut contenir des centaines voire des milliers de variables aléatoires, rendant impossible de faire des graphiques pour chaque variable.
- 😀 Les mesures agrégées, telles que les moyennes et écarts-types, sont nécessaires pour synthétiser et résumer l'information des grandes quantités de données.
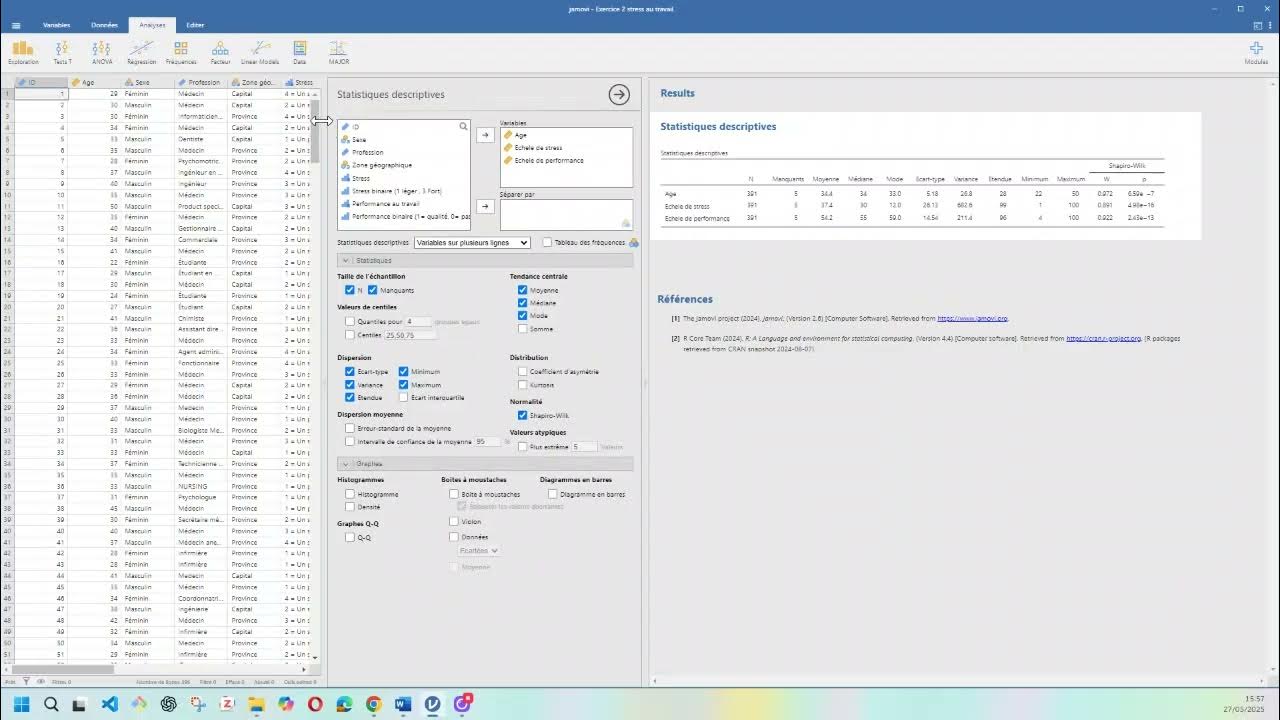
- 😀 La mesure de position permet de savoir autour de quel âge se situe une population, ce qui est essentiel pour analyser des données démographiques, par exemple la consommation de cannabis en France.
- 😀 Les mesures de dispersion, telles que l'écart-type et les quartiles, aident à comprendre la variabilité des données dans un échantillon.
- 😀 La moyenne et la médiane sont deux mesures de position, mais la médiane est plus robuste face aux valeurs extrêmes.
- 😀 La médiane divise les données en deux parties égales, tandis que la moyenne est le centre de gravité des données, et les deux peuvent être différentes si les données sont asymétriques.
- 😀 La médiane est intuitive et facile à comprendre, mais elle peut être plus difficile à calculer, surtout pour de grands ensembles de données.
- 😀 La moyenne a des propriétés mathématiques intéressantes et est souvent utilisée pour des calculs pratiques comme les prévisions économiques ou les financements d'hôpitaux.
- 😀 L'écart-type est une mesure de dispersion qui a une interprétation physique, mais il n'est pas toujours intuitif pour les utilisateurs.
- 😀 La variance, et donc l'écart-type, a des propriétés mathématiques qui facilitent les calculs pour de grands échantillons, ce qui était crucial avant l'informatique.
Q & A
Pourquoi est-il difficile de représenter graphiquement toutes les variables d'un jeu de données moderne ?
-Parce que les fichiers de données peuvent contenir des centaines ou milliers de variables aléatoires, et produire autant de graphiques serait illisible et inefficace.
Quelles sont les deux grandes catégories de mesures statistiques utilisées pour résumer des données ?
-Les mesures de position, qui indiquent autour de quelle valeur se situent les données, et les mesures de dispersion, qui indiquent à quel point les données sont regroupées ou dispersées.
Quelle est la mesure de position adaptée pour une variable qualitative ?
-Pour une variable qualitative, une mesure de position consiste à calculer le pourcentage de chaque modalité de la variable.
Comment se définit la moyenne pour une variable quantitative ?
-La moyenne est la somme de toutes les observations divisée par le nombre total d'observations, représentant le centre de gravité des données.
Quels sont les avantages de la médiane par rapport à la moyenne ?
-La médiane est intuitive et robuste aux valeurs extrêmes, car elle divise les données en deux parties égales sans être influencée par des valeurs anormalement grandes ou petites.
Dans quel cas la moyenne peut-elle être préférée à la médiane ?
-La moyenne peut être préférée pour des raisons pratiques ou comptables, par exemple pour calculer la durée moyenne de séjour à l'hôpital et estimer les ressources ou les coûts totaux.
Qu'est-ce que l'intervalle interquartile et quelle est son utilité ?
-L'intervalle interquartile est la différence entre le troisième quartile (Q3) et le premier quartile (Q1), regroupant 50% des observations autour de la médiane, utile pour mesurer la dispersion et visualiser les données dans un boxplot.
Comment se calcule l'écart-type et que mesure-t-il ?
-L'écart-type est la racine carrée de la variance, qui est la moyenne des carrés des écarts à la moyenne. Il mesure la dispersion des données autour de la moyenne et possède des propriétés mathématiques solides.
Pourquoi l'écart-type est-il historiquement préféré à une mesure plus intuitive de dispersion ?
-Parce qu'il est facile à calculer même pour de grands échantillons, grâce à la formule variance = moyenne des carrés – carré de la moyenne, ce qui simplifiait énormément les calculs manuels avant l'informatique.
Quelle est la relation entre moyenne, médiane et symétrie d'une distribution ?
-Si la distribution est symétrique, la moyenne et la médiane sont égales. Si la distribution est asymétrique, la moyenne et la médiane peuvent différer de manière significative.
Comment les utilisateurs interprètent-ils l'écart-type dans une distribution normale ?
-Dans une distribution normale, l'écart-type permet d'estimer qu'environ deux tiers des données se situent dans l'intervalle [moyenne – écart-type, moyenne + écart-type], ce qui donne un sens pratique à cette mesure.
Quelles propriétés font de la moyenne un paramètre mathématiquement intéressant ?
-La moyenne possède des propriétés géométriques et physiques (centre de gravité), est simple à calculer, et intervient dans de nombreux tests statistiques comme le test t.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示
Analyse descriptive des variables quantitatives

Différences entre méthodes quantitatives et méthodes qualitatives

✅ Statistique descriptive : premier cours (notions de base)

Projet Expérimental et Numérique: l'acquisition et l'analyse de résultats

Conseils de data-driven design + mon retour d'expérience sur cette table ronde - Podcast

1.3 - Analyse exploratoire des données
5.0 / 5 (0 votes)
