Data Warehouse vs Data Lake | Explained (non-technical)
Summary
TLDRThis video explains the key differences between Data Lakes and Data Warehouses, two critical components of modern data architecture. A Data Lake stores raw, unstructured data from various sources, while a Data Warehouse organizes and structures this data for analysis and decision-making. The video also highlights the purpose of data architecture, focusing on consolidation, understanding data events, and enabling better business decisions. By clarifying how these systems work together, the video provides viewers with a better understanding of how businesses use data to drive insights and decisions.
Takeaways
- 😀 Data engineering focuses on managing data through architecture, and two key concepts are data lakes and data warehouses.
- 😀 Data lakes are a central repository for raw, unstructured data from various sources like applications, third-party tools, and more.
- 😀 Data lakes support multiple data formats such as JSON, CSV, video files, and text files, without any standardized structure.
- 😀 The goal of data lakes is to constantly capture and store data for later use, reducing the traditional waiting time seen in ETL processes.
- 😀 Data warehouses follow data lakes in the data pipeline, focusing on transforming raw, unstructured data into clean, organized, and structured data.
- 😀 A data warehouse allows for easier reporting and decision-making by converting unorganized data into a single source of truth.
- 😀 Dimensional modeling, star schemas, normalization, and denormalization are some techniques used in data warehouses to structure the data.
- 😀 Data warehouses update their data on a fixed cadence, pulling data from the lake, transforming it, and applying business logic.
- 😀 A key purpose of data warehouses is to improve data performance, making it faster and more consistent for use in decision-making.
- 😀 A modern data architecture includes both data lakes and data warehouses as critical components to manage and analyze large amounts of data efficiently.
Q & A
What are the three main goals of data architecture?
-The three main goals of data architecture are: 1) Consolidating data from various sources, 2) Analyzing events and what happened with that data, and 3) Using the data to make better business decisions.
What is the purpose of a data lake?
-The purpose of a data lake is to act as a central landing zone where raw, unstructured data from various source systems is stored. It is a place for dumping data in all different formats without consistent structure, allowing for easy and continuous data ingestion.
How does a data lake handle different data formats?
-A data lake can handle various data formats such as JSON, video files, text files, and CSVs. It doesn't require a consistent format for data and can store it in whatever format is being generated from source systems.
What are some common storage locations for a data lake?
-Common storage locations for a data lake include Amazon S3 buckets, Azure storage, and modern cloud databases like Snowflake. These allow for flexible storage options based on the business's needs.
What is the main difference between a data lake and a data warehouse?
-A data lake stores raw, unstructured data from various sources, while a data warehouse stores cleaned, structured, and organized data that has been processed and transformed for reporting and decision-making.
How does a data warehouse work in the data architecture?
-A data warehouse comes after the data lake in the data architecture. It takes the raw data from the data lake and transforms it into a structured, organized form, often using schemas and tables, to create a single source of truth for reporting and decision-making.
What types of data structures are typically used in a data warehouse?
-Data warehouses typically use structured data formats like tables, schemas, and relationships between keys. Common models include dimensional modeling, star schema, and normalization/denormalization strategies.
Why is it important to clean and organize data in a data warehouse?
-Cleaning and organizing data in a data warehouse is essential because it turns raw, unstructured data into a usable, consistent format that is easier to interpret, improves performance, and allows businesses to make better decisions based on accurate and reliable information.
How often is data typically updated in a data warehouse?
-Data in a data warehouse is typically updated on a set cadence, such as once an hour or once a day, by pulling data from the data lake, transforming it, and applying business logic.
What is the role of facts and dimensions in a data warehouse?
-In a data warehouse, facts and dimensions are used in data modeling. Facts represent measurable data, while dimensions provide context to the facts. For example, sales data could be the fact, and customer information would be the dimension providing more context about the sales.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآن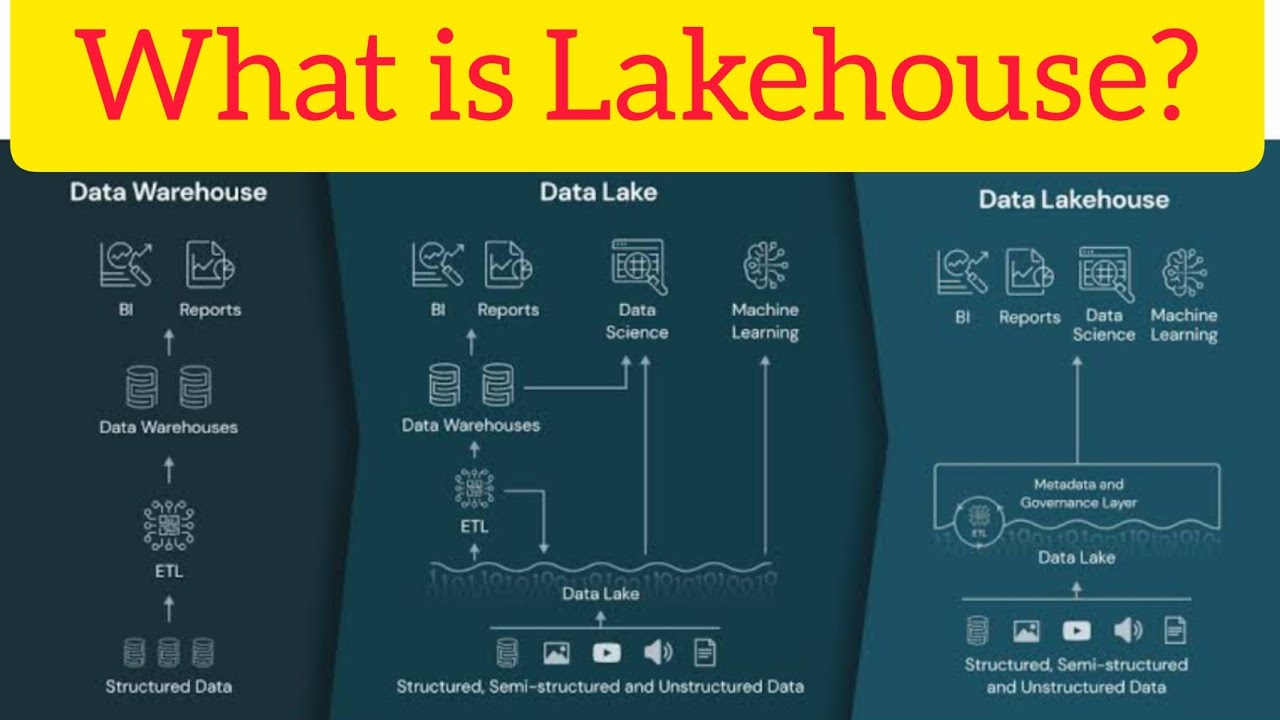





5.0 / 5 (0 votes)
